
In general, my research spans algorithmic game theory, online learning, multi-agent reinforcement learning and computational complexity, as well as their applications to agentic AI and economics. The ultimate goal of my research is to develop theoretically principled solutions to algorithmic challenges, drawing inspiration from modern decision-making environments and AI, in order to bridge the gap between real-world application and fundamental computational understanding. Below, I outline the main research pillars of my work:
The complexity of finding stationary points and equilibria
This research pillar investigates the complexity of fundamental problems in non-convex optimization and algorithmic game theory:
Stationary Points: Our goal is to advance the computational understanding of finding second-order stationary points (SOSPs) in non-convex optimization. Such points are of remarkable interest for the ML/optimization community, since widely used optimizers—including Gradient Descent—can theoretically get stuck in first-order stationary points (FOSPs) that may correspond to problematic strict saddle points. Therefore, our main research question is the following:
What is the computational complexity of avoiding strict saddle points both in unconstrained and constrained non-convex optimization?
Our contribution and its significance
We proved that the problem is PLS-complete both in constrained (arXiv 2026) and unconstrained (ICML 2024) optimization; thereby resolving important open questions in the field. Our results imply that unless PLS $\subseteq$ PPAD (which is widely believed not to hold), there exists no iterative algorithm with a continuous, efficiently implementable update rule (such as Gradient Descent or Newton’s method) for finding SOSPs! Last but not least, our result in the constrained setting yields the first problem defined in a compact domain to be shown PLS-complete beyond the canonical Real-LocalOpt.
Equilibrium Computation in Markov (Stochastic) Games: We study the computational complexity of equilibria in Markov games; i.e., the game-theoretic framework capturing the setting of multi-agent reinforcement learning. The ultimate goal here is to identify the computational barriers of computing equilibria in Markov games and further explore settings where we can provably escape the PPAD-hardness inherent in general normal-form games.
What does an equilibrium look like? To define an equilibrium notion in a Markov game, it is crucial to define (i) how strategies for the game are encoded; and (ii) what deviations from a putative equilibrium one considers. A policy is Markovian if its prescription depends only on the current state, rather than on the full history of play. Policies can also be nonstationary, allowing this prescription to vary with time, or stationary, using the same prescription whenever the same state is visited. For finite discounted stochastic games, stationary Markov Nash equilibria (NE) are known to exist; however, they are computationally intractable due to the PPAD-hardness of NE in normal-form games. Stationary Markov coarse correlated equilibria (CCE) also exist as a superset of stationary Markov NE. Stationary Markov CCE provide a natural solution concept: they give a compact, time-homogeneous description of behavior, and their incentive constraints can be expressed entirely in terms of the same stationary policy.
Prior work has established PPAD-hardness for computing stationary Markov CCE in two-player general-sum discounted stochastic games. The reductions used in these hardness results rely on turn-based constructions in which each state is controlled by a single player, with control alternating across states, so that every player controls both rewards and transitions at some states. This structure effectively collapses Markov CCE to NE, thereby allowing hardness for NE to immediately transfer to CCE. A fundamental subclass of stochastic games not captured by the above negative results is that of single-controller Markov games, a model which goes back to classical work on stochastic games from the 80s and generally does not satisfy this equilibrium collapse property. Therefore, a key open question is the following:
Is the hardness of stationary Markov CCE an artifact of alternating transition control, or does it persist even when the state dynamics have single-controller structure?
Our contribution and its significance
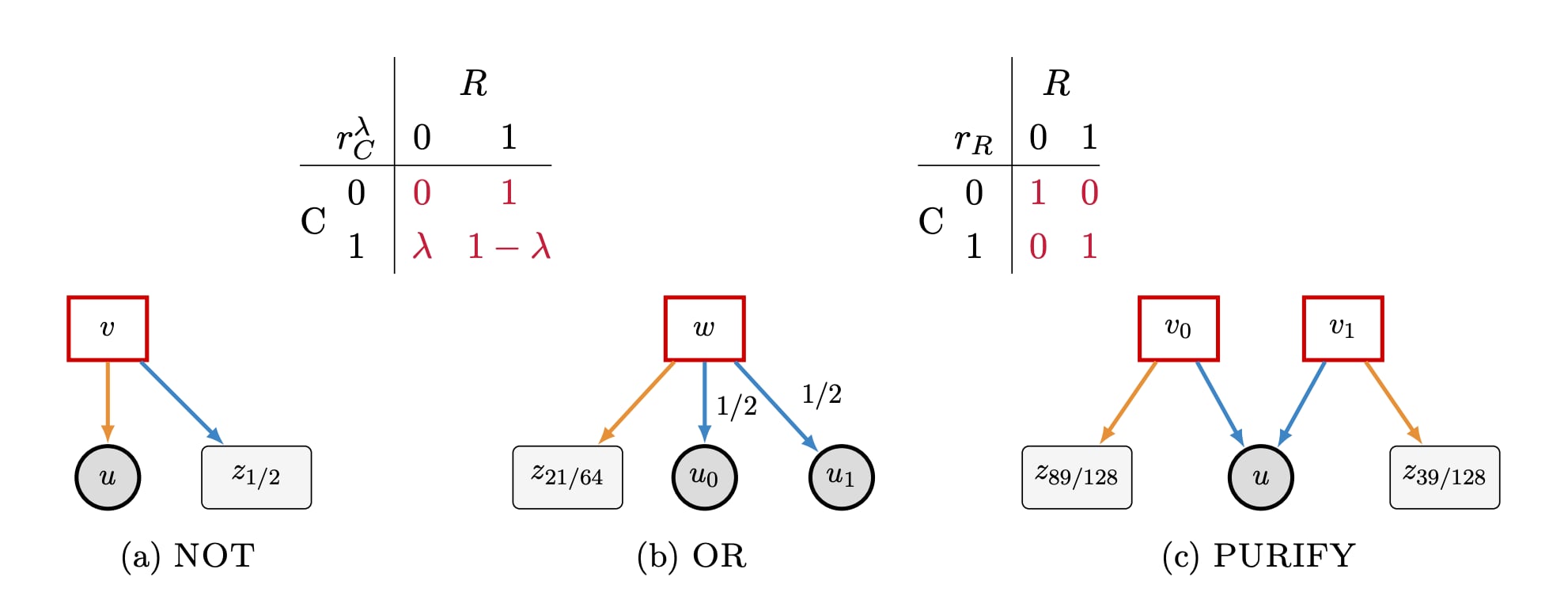
In (arXiv 2026), we proved that computing an approximate stationary Markov CCE in single-controller Markov games is PPAD-complete. Our result shows that neither the switching-controller structure nor the equilibrium collapse property are what actually drives the hardness of stationary Markov CCE; it is enough that one player solely controls the transitions while both players affect rewards. Technically, our result is the first to show PPAD-hardness for computing CCE without relying on equilibrium collapse phenomena or reductions from hard Nash instances.
Game Theory & Online Learning: No-regret learning under imperfect information
In this research pillar, we investigate the convergence properties and structural guarantees of no-regret dynamics within environments characterized by information asymmetry and partial observability. Specifically, I’m particularly interested in studying decentralized online learning in games under imperfect information, where no-regret dynamics translate to computing game-theoretic equilibrium notions—such as Nash equilibria or correlated equilibria—as well as adversarial settings where the learner competes against powerful, best-in-hindsight benchmarks.
Main results
- Learning under combinatorial structure: We provided a kernelization-based algorithmic framework for learning in polyhedral games under imperfect information (i.e., bandit and semi-bandit feedback), which facilitates efficient implementation and sampling for the classical combinatorial bandit GeometricHedge/ComBand algorithm and the celebrated Exp3-IX algorithm (NeurIPS 2025). Our work establishes state-of-the-art results in terms of the game parameters for learning coarse correlated equilibria across a wide array of games, such as Colonel Blotto and congestion games. Moreover, we provided the first efficiently implementable algorithm for adversarial combinatorial bandits that achieves no swap regret (that is, a strong notion of regret associated with correlated equilibria) with polylogarithmic dependence on the large action size of combinatorial bandits (AISTATS 2026).
- Learning under hidden-convex structure: We study online learning with nonconvex losses that become convex under an unknown nonlinear reparameterization. In (arXiv 2026), we prove that Online Gradient Descent achieves optimal regret $\mathcal{O}(\sqrt{T})$ in the adversarial setting, matching the classical rate for online convex optimization; thereby improving over the previous established analysis that achieved $\mathcal{O}(T^{2/3})$ regret. We also characterize the geometric compatibility needed for this equivalence, show a linear-regret barrier when it fails, and extend the framework to one-point bandit feedback with $\mathcal{O}(T^{3/4})$ expected regret.
Agentic AI & Multi-agent reinforcement learning
The main direction of this research pillar is to study how AI agents can effectively coordinate toward shared objectives in complex cooperative environments. In particular, we develop novel algorithmic frameworks based on multi-agent reinforcement learning (MARL). Our ultimate goal is to advance our understanding of the limits of decentralized decision making, as well as to explore agent/state modelling paradigms for minimizing the communication requirements of multi-agent systems, particularly under safety constraints.
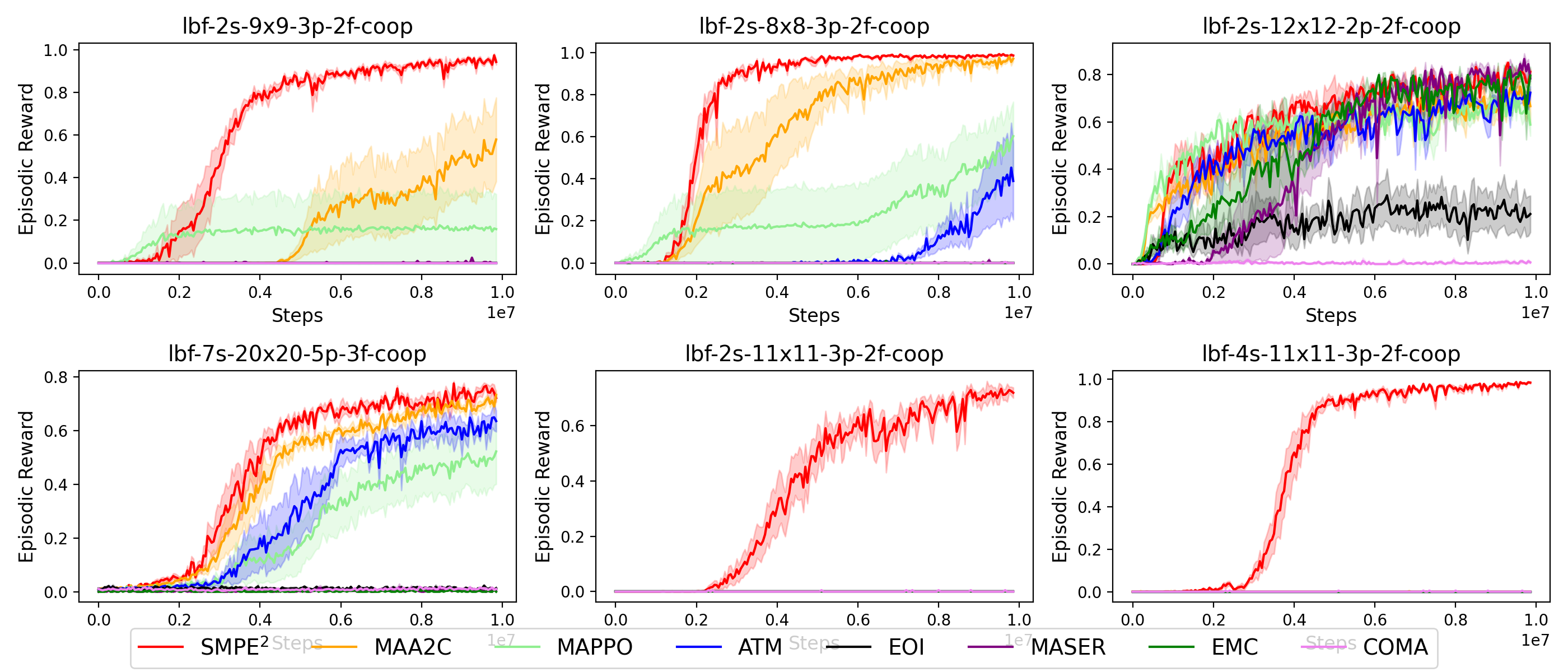
Main results
- A novel MARL algorithm, called SMPE, which leverages a novel state modelling framework for enhancing policy optimization and joint exploration in distributed partially observable environments where agents share no communication channels during execution (ICML 2025). Experimentally, we demonstrated that our method outperforms state-of-the-art MARL algorithms in complex fully cooperative tasks from the well-established MPE, LBF, and RWARE benchmarks.
- In (AAMAS 2025), we highlight the crucial need for expanding systematic MARL evaluation across a wider array of benchmarks by showing that many algorithms, hailed as state-of-the-art mostly on the widely used SMAC benchmark, may significantly underperform standard MARL baselines on fully cooperative testbeds.